The Engineered Chaos Bugs Fear

Fuzzing is one of the most practical ways to find bugs that unit tests miss, especially in large code bases.
At a basic level, a fuzzer repeatedly feeds a series of not-so-randomized inputs into a program with the objective of identifying crashes, failed assertions, unexpected behavior, or broken assumptions. Many modern languages now have good fuzzing support built into or near the standard developer workflow.
Go has native fuzzing support in its testing package. Rust has a very mature fuzzing ecosystem, including tools built around libFuzzer, AFL-style fuzzing, and other feedback-driven approaches. Same goes for Swift, where Apple introduced native fuzzing support and integrated libFuzzer directly into the compiler.
The goal is not to throw random "garbage" at the program and hope something breaks. Sophisticated fuzzers are usually coverage-guided: they learn which inputs reach new parts of the code, mutate those inputs, and gradually explore deeper paths. That makes fuzzing especially good at finding the strange edge cases human-written or AI-generated unit tests usually miss.
In real systems, useful fuzzing often requires more than raw random bytes. If you are testing a parser, protocol, backend service, or a distributed system component, most totally random inputs are malformed and get rejected immediately. The fuzzer never reaches the interesting logic.
This is where harnesses matter.
A well-designed harness generates inputs that mimic the real world well enough to get past the front door, while still exploring combinations humans would not think to test.
Some of the most interesting fuzzing work we do at Runtime Verification involves building these harnesses for complex systems: structured inputs, sequences of actions, state transitions, and data that has to satisfy certain constraints before the software will process it.
Take Monad, which ran one of the most extensive and rigorous security campaigns last year, leading up to their mainnet. By the time we joined, multiple teams had already built harnesses covering the VM, the staking precompile, the trie, and more. Our job was to review what was in place, find the gaps, and push the harnesses further. We rebuilt one of the compiler harnesses to use coverage-guided fuzzing, which hit a failure case in minutes that the original generator had missed after hours of runtime.
That is the value of fuzzing on a project this mature: it keeps surfacing things the eye and the existing tests have already moved past.
// embedded tweet from Monad on anything security related here maybe, again to break up the text
Differential fuzzing is another powerful technique. Instead of asking “does this program crash?”, we ask “do these two implementations behave the same?”.
This is especially useful when a system is:
- being ported to another language
- rewritten for performance
- rebuilt to remain compatible with an existing implementation.
If the old version and the new version produce different outputs for the same input, you have found a lack of parity.
The difficulty is that the test has to mean the same thing in both environments, which usually requires deep understanding of both languages, runtimes, and edge-case behavior.
Last year we also audited Mithril, a Go-based Solana validator client. When a second client joins a live network, it has to behave exactly like the reference, or the chain forks. That is what differential fuzzing is built for. The approach was straightforward: feed the same inputs into Mithril and into Agave, the Rust reference, and compare the outputs.
Any disagreement is a lead worth investigating, and the harness, built by Jump in this case, made those leads easy to surface across transaction execution, the ELF loader, and the VM interpreter. This type of an in-depth review produced a highly detailed report for the Mithril team, when all was said and done.
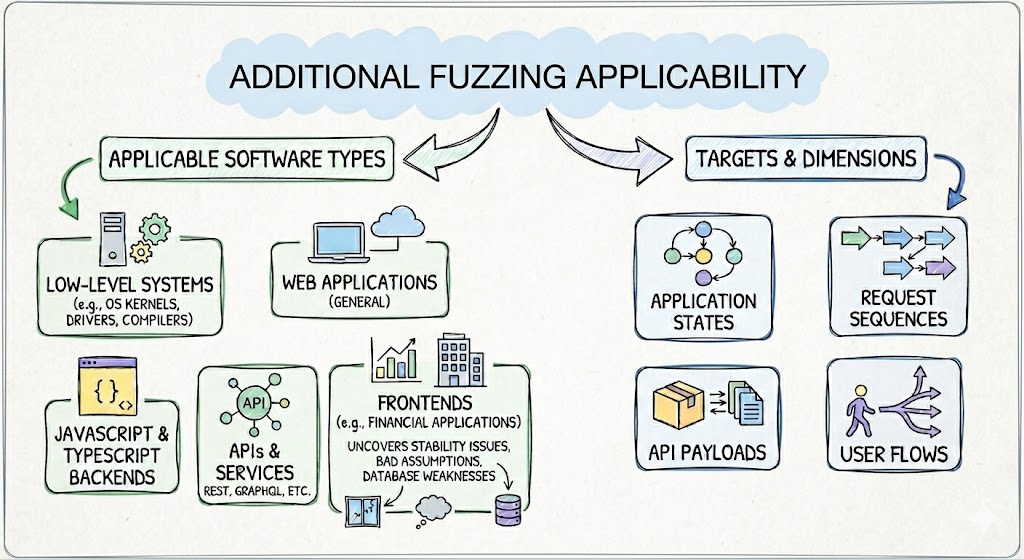
Fuzzing does not need to be limited to low-level systems code, however.
We have used fuzzing successfully on financial application frontends, where the tests uncovered stability problems, bad assumptions, and database weaknesses that ordinary UI testing had missed.
We're formal methods people. We like proving correctness when the system and tooling make that possible. But full formal verification can be expensive and time-consuming, and careful scoping is required to make verification practical.
Fuzzing is often the happy medium.
We can model the system, identify the invariants, build meaningful fuzzing harnesses, and then run the software through millions or billions of adversarial test cases. It will not prove correctness the way formal verification would, but it can uncover a large class of edge cases before attackers, users, or production traffic do.
And this matters even more in the AI era.
As AI gets better at writing fuzzers, attackers will get better at using them too. The cost of finding edge-case inputs, broken assumptions, and exploitable edge cases is falling quickly. Teams building critical software should not wait for the adversarial testing to happen from the outside.
And to ease the pain of running and tracking results, Kontrol-as-a-Service (our all in-one place for fuzzing), can execute runs, track coverage, report bugs, and give teams a clearer view into how much of the system has actually been exercised.
If you are building software that cannot fail, fuzzing must be part of your assurance strategy.