Why K
Unlike natural language, which allows interpretation and miscommunication, programming languages are meant to tell computers precisely what to do. Without a rigorous definition of a programming language that unambiguously says what each program does, also called a formal semantics, it is impossible to guarantee reliable, safe or secure operation of computing systems. K is a framework that allows you to define, or implement, the formal semantics of your programming language in an intuitive and modular way. Once you do that, K offers you a suite of tools for your language, including both an executable model and a program verifier.
Why Formal Semantics
Formal semantics of programming languages is a very old field of study, started long before many of us were born, in late 60's (Floyd-Hoare, or axiomatic semantics) to 70's (Scott-Strachey, or denotational semantics) and 80's (various types of operational semantics).
Unfortunately, formal semantics have a negative connotation among practitioners, who think that formal semantics of real programming languages are hard to define, difficult to understand, and ultimately useless. This is partly fueled by the fact that most formal semantics require a solid mathematical background to be understood and even more math to be defined, use cryptic notations that make little sense to non-logicians, such as backwards A and E symbols and a variety of Greek letters, and in the end sell themselves as "helping you better understand your language" and nothing else. To understand their language even better, some semanticists define two or more formal semantics for the same language and then carry out complex proofs of equivalence between the various semantics, some taking years and PhDs to complete. Not unsurprisingly, most language designers forgo defining a formal semantics for their language altogether, and just implement adhoc interpreters, compilers or whatever tools are desired or needed for their languages manually, without any correctness guarantees. The consequence is that programs in such languages may end up manifesting unexpected behaviors after they are deployed, sometimes with catastrophic consequences. We want to change that. In fact, without a formal definition of the programming language, it is literally impossible to even state what it means for a program to behave correctly.
Ideal Language Framework
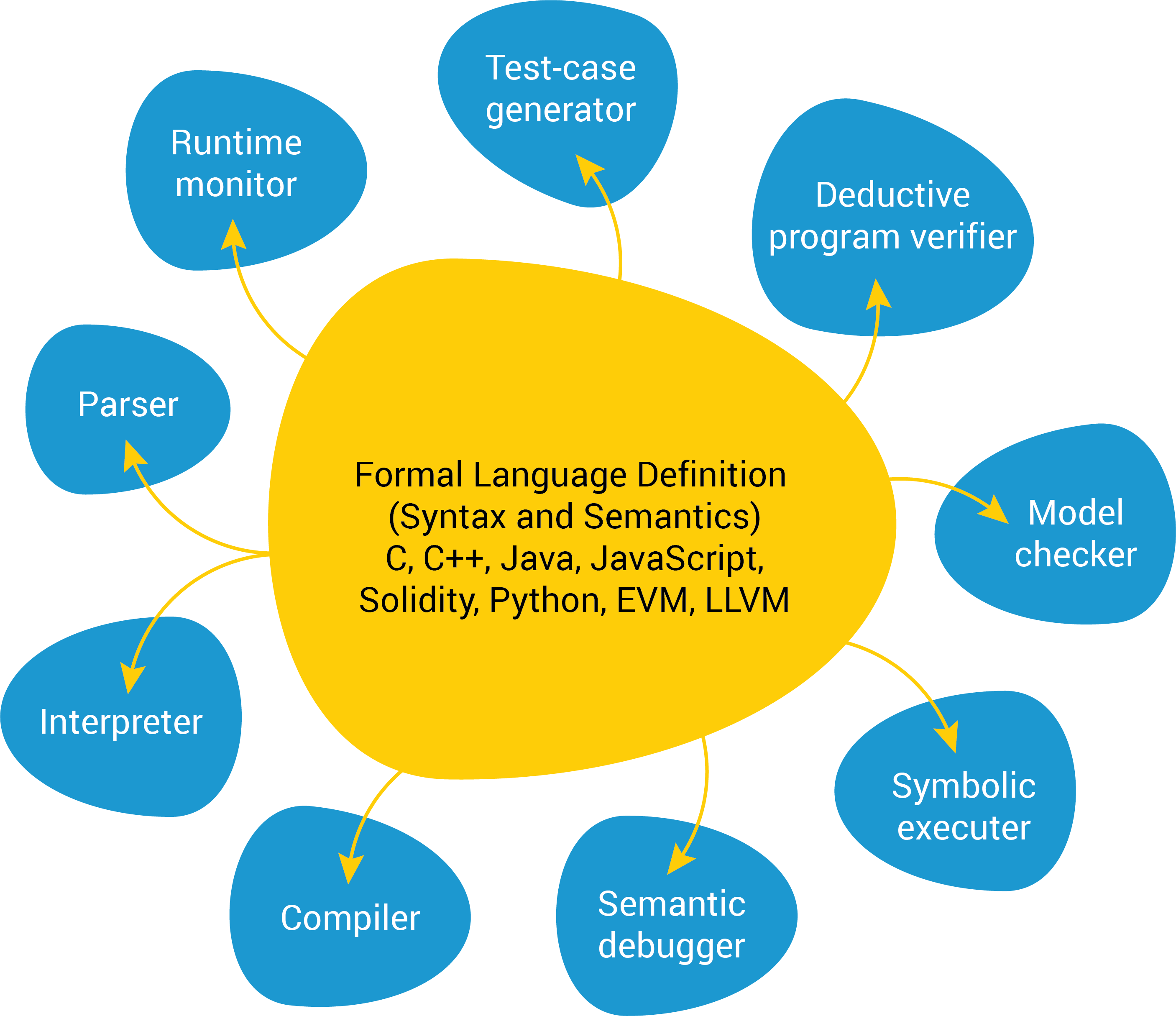
The K Framework was born from our firm belief that an ideal language framework is possible. Specifically, that programming languages must have formal definitions, and that tools for a given language, such as interpreters, compilers, state-space explorers, model checkers, deductive program verifiers, etc., are derived from just one reference formal definition of the language, at no additional cost specific to that language. No other semantics for the same language should be needed. The framework (meta-)language used for formally defining programming languages must be: user-friendly, so language designers use it as a natural means to create and experiment with their languages; mathematically rigorous, so the resulting language definitions can be used as a basis for formal reasoning about programs; modular, so the defined languages are easy to extend with new features without having to revisit already defined features; and expressive, so we can define any programming language with arbitrarily complex features. The generic tools instantiated for any given language must be correct-by-construction, so we can trust their results, and efficient, so there is no need for wasting time and energy to implement language-specific tools.
The above is the ideal scenario and we believe that there is enough evidence that it is within our reach to achieve in K in the short term. For example, the RV-Match tool is a commercial dynamic analysis tool generated completely automatically from the formal K semantics of the C language, which can detect more undefined behaviors than other tools specifically crafted for C and for this task. Similarly, the implementations of the KEVM and IELE virtual machines for the blockchain are generated automatically from their formal K semantics and have acceptable performance to be deployed on actual blockchains. Also, this OOPSLA'16 paper presents a program verification module of K which takes the respective formal semantics of C, Java, and JavaScript as input and yields automated program verifiers for these languages, capable of verifying challenging programs at performance comparable to that of state-of-the-art verifiers specifically crafted for those languages. Notably, the exact same language-agnostic program verifier, but this time instantiated with KEVM, the K semantics of the Ethereum Virtual Machine, is used commercially by RV to formally verify Ethereum smart contracts.
If you are new to this field, you are probably asking yourself "Why would it be any other way?". If you are theoretically inclined, you are probably thinking "Isn't it obvious that once I have a language definition giving a transition system for any program, that generic tools for transition systems can be used to obtain specialized tools for my language?". We agree. Unfortunately and almost unbelievably after half a century of research in this area, the state-of-the-art in programming languages is still to have no formal definition of the programming language, or to define a language by an adhoc untrusted translation to another language which may itself have no formal definition, and then each tool to implement its own projection of a hypothetical model of the language at the discretion of its developers, and the same tool for different languages, say a model checker, to re-implement the same algorithms and abstractions slightly adapted to each target language. And ironically, the resulting tool is then called a "formal analysis tool" or a "program verifier" for that language, and used to verify and validate safety critical software upon which our lives depend. We believe the time has come to put a stop to this nonsense and do things right! The ideal framework approach is possible and is practical. We are pursuing it with K.
Defining Languages in K
K is a rewrite-based executable semantic framework in which programming languages, type systems and formal analysis tools can be defined using configurations, computations and rules. Configurations organize the state in units called cells, which are labeled and can be nested. Computations carry computational meaning as special nested list structures sequentializing computational tasks, such as fragments of program. K (rewrite) rules make it explicit which parts of the term they read-only, write-only, read-write, or do not care about. This makes K suitable for defining truly concurrent languages even in the presence of sharing. Computations are like any other terms in a rewriting environment: they can be matched, moved from one place to another, modified, or deleted. This makes K suitable for defining control-intensive features such as abrupt termination, exceptions, concurrency or call/cc.
Toy Example 1: LAMBDA
As a toy example, below is the complete K definition of a simple call-by-value lambda calculus language with builtin arithmetic, conditional, let, letrec, and call/cc, which we refer to as LAMBDA:
module LAMBDA imports SUBSTITUTION syntax Val ::= Id | "lambda" Id "." Exp [binder] syntax Exp ::= Val | Exp Exp [strict, left] | "(" Exp ")" [bracket] syntax KVariable ::= Id syntax KResult ::= Val rule (lambda X:Id . E:Exp) V:Val => E[V / X] syntax Val ::= Int | Bool syntax Exp ::= Exp "*" Exp [strict, left] | Exp "/" Exp [strict] > Exp "+" Exp [strict, left] > Exp "<=" Exp [strict] rule I1 * I2 => I1 *Int I2 rule I1 / I2 => I1 /Int I2 rule I1 + I2 => I1 +Int I2 rule I1 <= I2 => I1 <=Int I2 syntax Exp ::= "if" Exp "then" Exp "else" Exp [strict(1)] rule if true then E else _ => E rule if false then _ else E => E syntax Exp ::= "let" Id "=" Exp "in" Exp rule let X = E in E' => (lambda X . E') E syntax Exp ::= "letrec" Id Id "=" Exp "in" Exp | "mu" Id "." Exp [binder] rule letrec F:Id X = E in E' => let F = mu F . lambda X . E in E' rule mu X . E => E[(mu X . E) / X] syntax Exp ::= "callcc" Exp [strict] syntax Val ::= cc(K) rule <k> (callcc V:Val => V cc(K)) ~> K </k> rule <k> cc(K) V ~> _ => V ~> K </k> endmodule
Note that syntax is defined using conventional BNF, with terminals in quotes. The | separates productions of same precedence, while > states that the previous productions bind tighter than the subsequent ones. A parser is generated automatically and is used to parse both the programs and the semantic rules; i.e., rules can use concrete syntax. Syntax and rule declarations can be tagged with attributes. Some attributes have meaning for the parser, such as left for left associativity, others have semantic meaning, such as binder (used by the builtin variable-capture free substitution) and strict (which defines appropriate evaluation contexts). For K’s internal substitution to work out of the box, we also need to tell it which syntactic categories act as variables, by subsorting them to KVariable. Similarly, for efficiency we need to tell it which categories build non-reducible results by subsorting to KResult. Most of the semantic rules are self-explanatory. The call/cc rules use local rewriting: rewriting takes place in context, specifically in the <k> cell, and not at the top level. The binary ~> construct allows us to sequentialize computational tasks (can be thought of as a bind monad construct) and is being internally used to efficiently handle evaluation contexts. This gives K convenience and modularity in language definitions.
Toy Example 2: IMP
Below is another toy example, the K semantic definition of the classic IMP language. IMP is considered a folklore language, without an official inventor, and has been used in many textbooks and papers, often with slight syntactic variations and often without being called IMP. It includes the most basic imperative language constructs, namely basic constructs for arithmetic and Boolean expressions, and variable assignment, conditional, while loop and sequential composition constructs for statements.
We start by defining the IMP syntax, in a separate module:
module IMP-SYNTAX syntax AExp ::= Int | Id | AExp "/" AExp [left, strict] > AExp "+" AExp [left, strict] | "(" AExp ")" [bracket] syntax BExp ::= Bool | AExp "<=" AExp [strict] | "!" BExp [strict] > BExp "&&" BExp [left, strict(1)] | "(" BExp ")" [bracket] syntax Block ::= "{" "}" | "{" Stmt "}" syntax Stmt ::= Block | Id "=" AExp ";" [strict(2)] | "if" "(" BExp ")" Block "else" Block [strict(1)] | "while" "(" BExp ")" Block > Stmt Stmt [left] syntax Pgm ::= "int" Ids ";" Stmt syntax Ids ::= List{Id,","} endmodule
Note that && is strict only in its first argument, because we want to give it a short-circuit semantics. An IMP program declares a set of variables and then executes a statement in the state obtained after initializing all those variables to 0. K provides builtin support for generic syntactic lists: List{Nonterminal,terminal} stands for terminal-separated lists of Nonterminal elements.
Next we define the semantics of IMP, in a module importing the syntax module:
module IMP imports IMP-SYNTAX syntax KResult ::= Int | Bool configuration <T color="yellow"> <k color="green"> $PGM:Pgm </k> <state color="red"> .Map </state> </T> // AExp rule <k> X:Id => I ...</k> <state>... X |-> I ...</state> rule I1 / I2 => I1 /Int I2 requires I2 =/=Int 0 rule I1 + I2 => I1 +Int I2 // BExp rule I1 <= I2 => I1 <=Int I2 rule ! T => notBool T rule true && B => B rule false && _ => false // Block rule {} => . [structural] rule {S} => S [structural] // Stmt rule <k> X = I:Int; => . ...</k> <state>... X |-> (_ => I) ...</state> rule S1:Stmt S2:Stmt => S1 ~> S2 [structural] rule if (true) S else _ => S rule if (false) _ else S => S rule while (B) S => if (B) {S while (B) S} else {} [structural] // Pgm rule <k> int (X,Xs => Xs);_ </k> <state> Rho:Map (.Map => X|->0) </state> requires notBool (X in keys(Rho)) rule int .Ids; S => S [structural] endmodule
IMP only has two types of values, or results of computations: integers and Booleans. We used the K builtin variants for both of them. The configuration of IMP (lines 5-8) is trivial: it only contains two cells, one for the computation and another for the state. For good encapsulation and clarity, we placed the two cells inside another cell (labeled T, from "top"). The configuration variable $PGM tells the K tools where to place the program. Specifically, the command krun program parses the program and places the resulting abstract syntax tree in the k cell before invoking the semantic rules described in the sequel. The .Map in the state cell is K’s way to say "nothing". Technically, it is a constant which is the unit, or identity, of all maps in K (similar dot units exist for other K structures, such as lists, sets, multi-sets, etc.).
The rule for variable lookup, at line 11 above, makes again use of K's local rewriting. Program variable X is looked up in the state by matching a binding of the form X |-> I in the state cell. If such a binding does not exist, then the rewriting process will get stuck. Thus our semantics of IMP disallows uses of uninitialized variables. Note that the variable to be looked up is the first task in the k cell (the cell is closed to the left and open to the right), while the binding can be anywhere in the state cell (the cell is open at both sides). There is nothing special about the rules for arithmetic operators, except perhaps to notice the short-circuited semantics of &&.
There is one rule per statement construct except for if, which needs two rules. The empty block {} is simply dissolved; the . is the unit of the computation list structure K, that is, the empty task. Similarly, the non-empty blocks are dissolved and replaced by their statement contents, thus effectively giving them a bracket semantics; we can afford to do this only because we have no block-local variable declarations yet in IMP. The structural attribute tells the K tools that those rules structurally rearrange the computation structure, and they should not be considered to count as computational steps in the resulting transition systems; this is useful in order to cut the number of possible program behaviors in some of the K tools. The rule of variable assignment contains two local rewrites, one in the computation dissolving the assignment and another in the state updating the variable, and only applies if the variable is declared; otherwise the semantics will get stuck. Sequential composition is simply structurally translated into K’s builtin task sequentialization operation. The while loop semantics is given by unrolling.
Finally, the last two rules above give the semantics of IMP programs. The body statement is executed in a state initializing all the declared variables to 0. Since K’s syntactic lists are internally interpreted as cons-lists (i.e., lists constructed with a head element followed by a tail list), we need to distinguish two cases, one when the list has at least one element and another when the list is empty. In the first case we initialize the variable to 0 in the state, but only when the variable is not already declared (all variables are global and distinct in IMP). We prefer to make the second rule structural, thinking of dissolving the residual empty int; declaration as a structural cleanup rather than as a computational step.
Real Languages Defined in K
K scales. Several real languages have been defined following a style similar to the above. We are aware of the following (please let us know if we missed any):
-
C (github, PLDI'15 paper, POPL'12 paper).

A complete formal semantics of the ISO C11 standard has been given by Chucky Ellison, Chris Hathhorn and Dwight Guth together with collaborators, whose goal was to define all the undefined behaviors of C. This semantics powers the commercial RV-Match tool (CAV'16 paper), which aims at mathematically rigorous dynamic checking of C program compliance with the ISO C11 Standard. A program compiled and executed using RV-Match will catch many undefined behavior errors, in the same style as Valgrind or UBSan, ASan, etc., but can also catch a number of other even more subtle errors that result in undefined, unspecified, or implementation-defined behavior. The development of RV-Match has been funded by NASA, NSF, DARPA, Boeing, Toyota and Denso, and its capability is critical because many of the undefined behaviors are not only unintended, but also subject to change if you switch to a new target platform, compiler, or compiler version or optimization. A C program that seems to run perfectly in one environment can crash or behave incorrectly in another environment.
-
Java (github, POPL'15 paper).

A complete executable formal semantics of Java has been defined by Denis Bogdanas, whose goal was to define all the features of Java 1.4. The semantics was split into a static semantics and a dynamic semantics, and it was extensively tested using a test suite that was developed in parallel with the semantics, in a test driven development methodology. This test suite itself was an important outcome of the project, because Java appears to have no publicly available conformance testsuite. The output of the static semantics is a preprocessed Java program, which is a valid program (but using a subset of Java) that is passed as input to the dynamic semantics for execution.
-
JavaScript (github, PLDI'15 paper).

A complete formal semantics of JavaScript was defined by Daejun Park and thoroughly tested against the ECMAScript 5.1 conformance test suite, passing all 2,782 core language tests. Interestingly, among the existing implementations of JavaScript at that time, only Chrome V8's passed all the tests. In addition to a reference implementation for the target language, a K semantics also yields a simple coverage metric for a test suite: the set of semantic rules it exercises. It turned out that the ECMAScript 5.1 conformance test suite failed to cover several semantic rules. The authors wrote tests to exercise those rules and thus found bugs in production JavaScript engines (Chrome V8, Safari WebKit, Firefox SpiderMonkey). Like other K semantics, the semantics of JavaScript is also symbolically executable, so it can be used for formal analysis and program verification. Several non-trivial JavaScript programs were verified and the overall approach was shown to find security vulnerabilities.
-
PHP (KPHP website, ECOOP'14 paper).

To address the problem of vulnerabilities in web applications due to PHP coding errors, as well as the lack of coverage and soundness of adhoc analysis tools, Daniele Filaretti and his collaborators have rightfully determined that a formal semantics of the PHP language was necessary. They have thus formalized the semantics of a substantial core of PHP in K, based on the official documentation and experiments with the Zend reference implementation. They validated their semantics by testing it against the Zend test suite, and used the formal analysis capabilities provided by the framework to do LTL model checking and symbolic execution of PHP programs.
-
Python (github, M.S. 2013 thesis).

Dwight Guth's M.S. thesis work was one of the first efforts that demonstrated the ability to formalize the semantics of complex programming languages in K. His semantics of Phython 3.3 provided an interpreter as well as analysis tools for exploring the state space of programs and performing static reasoning about programs, including formal verification. Guth's Python semantics has been thoroughly tested against a number of unit tests, and was demonstrated to perform as well as the reference implementation of Python, CPython, on those tests.
-
Rust (Singapore team website, Singapore team paper; Shanghai team website, Shanghai team paper).

According to its website at the time of this writing (May 28, 2018), Rust is a new systems programming language that runs blazingly fast, prevents segfaults, and guarantees thread safety. To maintain memory and thread safety while ensuring performance, Rust provides a set of safe constructors and an ownership mechanism. Neverthless, a formal semantics of the language is still necessary in order to formally verify Rust programs, with or without the safe constructs. There are currently two parallel efforts to formalize the semantics of Rust in K, one in Singapore (Shuanglong kan, David Sanan, Shang-Wei Lin, Yang Liu) and another in Shanghai (Feng Wang, Fu Song, Min Zhang, Xiaoran Zhu, Jun Zhang). Both semantics appear to be work in progress, but at least the set of safe constructs has been completely defined already, and preliminary experiments report on symbolic execution and formal verification of some programs.
A developing field of interest for the distributed systems and applied cryptography communities is that of smart contracts: self-executing financial instruments that synchronize their state, often through a blockchain. The rise of these technologies, however, has been marred by a series of costly bugs and exploits, making the blockchain community increasingly embrace the use of formal methods and rigorous program analysis tools. This trend holds great promise due to the relative simplicity of the current smart contracts. Recently, three virtual machine languages for the blockchain have been formally modeled or designed using K:
-
Ethereum VM (github, Jellopaper, CSF'18 paper).

A complete formal K semantics of the Ethereum Virtual Machine (EVM), referred to as KEVM, has been defined by Everett Hildenbrandt and his collaborators. They empirically evaluated the KEVM correctness and performance using the official Ethereum test suite, which includes more than 40,000 EVM programs. EVM is a bytecode stack-based language that all smart contracts on the Ethereum blockchain are compiled to and then executed using EVM interpreters. KEVM was initially planned to serve as a foundation for formal analysis and verification of smart contracts, and it is indeed actively used by RV for exactly that purpose, to commercially verify Ethereum smart contracts (e.g., for ERC20 compliance). What was intially unexpected was its execution performance: when run with the automatically generated (OCaml-based) interpreter of K, the EVM tests were only one order of magnitude slower than with the reference C++ implementation of the EVM. This suggests that VMs for the blockchain, and not only, can realistically be automatically generated from their formal semantics, correct-by-construction. To test this hypothesis, IOHK in collaboration with RV have just launched (on May 28th, 2018) a KEVM testnet as part of their Goguen project, where developers can experiment with executing any EVM smart contracts on a VM generated entirely and automatically from its formal semantics.
-
IELE (github).

IELE is a low-level language, meant to serve as a foundation for the third generation of blockchains. IELE was designed to address security and correctness concerns in Ethereum, making it easier to write contracts which do not leak or lock funds, while simultaneously enabling the similar mathematically rigorous formal proofs of smart contract correctness that KEVM brings to Ethereum. Inspired from both LLVM and EVM, IELE is built to become the foundation of an entire compiler backend pipeline, eventually allowing robust gas optimization of bytecode of contracts written in any high level language that compiles to IELE. The IELE language uses an LLVM-style textual representation that is designed to be human readable. It is pretty easy to even manually write contracts straight in IELE; see, e.g., this ERC20 token. There is also a Solidity to IELE compiler available. IELE was formally specified and designed using K from start to end, and was never implemented manually: the IELE VM was completely automatically generated from its formal semantics using the interpreter generation capability of K. Therefore, there is nothing to prove about the correctness of the IELE VM with respect to its formal specification: it is correct-by-construction. It is currently in the process of being deployed on a Cardano testnet by IOHK in collaboration with RV. IELE is one of the most important case studies for K, a living proof that automatically-generated, correct-by-construction implementations of languages is practically feasible.
-
eWASM (github).
Existing K Tools
Taking such a formal language definition as input, K generates a variety of tools for the defined language without any additional knowledge about the given language except its formal syntax and semantics. The most basic tool, needed as a frontend to any other tool, is the parser generator. For example, using the syntax declarations in the definition of IMP, K generates a parser that can parse IMP programs like the following:
int n, sum; n = 100; sum = 0; while (!(n <= 0)) { sum = sum + n; n = n + -1; }
One of the most useful K tools is its interpreter generator (or rewriter, or execution engine). Taking a K language definition as input, it generates an interpreter for that language. For example, assuming that the definition of IMP above is saved in a file imp.k, the command kompile imp.k generates an interpreter for IMP which is invoked with the krun command. Continuing our example, if the IMP sum program above is saved in a file sum.imp, then krun sum.imp executes the program and yields the final configuration
<T> <k> . </k> <state> n |-> 0 sum |-> 5050 </state> </T>
Note that the k cell is empty, meaning that the program was completely executed, or consumed. At the end of its execution, n is 0 and sum is the sum of numbers up to 100, as expected. This execution capability of K is crucial for testing language semantics, and thus for increasing confidence in the adequacy of a language semantics. The above indirectly illustrates another K tool which like the parser generator is used by almost any other tool, the K unparser. Indeed, the above configuration result uses concrete syntax to display the cells and their contents, although internally these are all represented as abstract data types; K also has the capability to display its results using abstract instead of concrete syntax, which helps users disambiguate in case the concrete syntax is ambiguous.
One of the major design decisions of K was to naturally support not only execution, but also full-fledged program verification for the defined languages. That is, to provide a language-independent reasoning infrastructure in addition to its language-independent execution infrastructure, which can then be used with any programming language by simply plugging in its semantics as a set of axioms. And, more importantly, to achieve the above in an ideal, mathematically grounded manner. That is, to have a fixed logic with a fixed sound and (relatively) complete proof system, where all the various programming languages become theories, about which we can reason using the fixed proof system, execution corresponding to just one particular proof for a reachability property. By "fixed logic" we therefore mean that it does not depend on any particular programming language. This is in sharp contrast to many logics used for program verification, such as Hoare logic, dynamic logic, or separation logic, which are in fact more like "design patterns": you have a "Hoare logic for Java", a "dynamic logic for C", a "separation logic for JavaScript", etc.
The logical foundation of K is reachability logic (see, e.g., this paper) for dynamic properties, which uses matching logic (see, e.g., this paper) for static properties. We do not discuss these logics here; instead we encourage the interested reader to consult the above-mentioned references. Here we only show how to do program verification with K. The first step is to specify what you want to prove. Specifications can be written using the already existing K rule syntax; both the rules used for giving the language semantics and the rules used to specify program properties are reachability rules in reachability logic, which is the only type of sentence that reachability logic supports. One useful way to think when writing specifications is the following: "supposing that I want to add the program or fragment of program as a new construct to my language, what would its semantics be?". Let us consider the IMP language and its sum.imp program discussed above. We claim that the following K rule properly captures the intended semantics of the sum program:
rule <k> while (!(n <= 0)) { sum = sum + n; n = n + -1; } => . ...</k> <state>... n |-> (N:Int => 0) sum |-> (S:Int => S +Int ((N +Int 1) *Int N /Int 2)) ...</state> requires N >=Int 0
This rule states the obvious: when executed with program variable n bound to (symbolic) value N and sum bound to S, when the loop exits n is bound to 0 and sum is bound to the properly incremented value. To verify the above using K, put both rules above in a module extending the IMP semantics and save it in a file, say sum-spec.k. Then invoke the krun tool with the option -prove on this file. It should return true. There is also an option to see all the queries that K makes to Z3 during the verification process.
New K Tools
LLVM backend
SBC
Test-Case Generation
Proof object generation