K vs. Coq as Language Verification Frameworks (Part 1 of 3)
Formally verifying programs, like verifying smart contracts in blockchain systems or verifying airplane flight controllers in embedded devices, is a powerful technique for assuring correctness and increasing reliability of systems. In this context, the question of “Why use K as opposed to Coq?” seems to come up quite often when discussing K with colleagues who may not be familiar with K, but have heard about or used Coq before. In this series of posts, we make an attempt at highlighting some of the important ways in which K and Coq differ as formal verification frameworks for languages through a working example. We hope to convey to the reader why we believe K is more suitable in this context. Before we continue, we’d like to note that we have extensive experience with Coq, both as users and as library/framework developers.
This post series is not meant to draw a foundational or detailed comparison of K and Coq. Indeed, the two frameworks are very different and have been developed over the years with different philosophies, objectives and design goals in mind, targeting different analysis and verification methods. We focus here on a particular class of applications, which is verifying programs written in some language, and illustrate differences between them through this lens.
K and Coq at Runtime Verification
Both Coq and K are very capable as language verification frameworks and we at Runtime Verification have been using them regularly to provide our formal modeling and verification services.
Examples of recent K-based developments include semantics of the Ethereum Virtual Machine KEVM and the generated interpreter and deductive verifier bundled in the Firefly toolset, a complete definition of a blockchain language IELE, a concrete model of Ethereum 2.0 Beacon Chain specification, and KWasm: a formal executable semantics of Web Assembly, among others.
Some recent Coq-based developments (not necessarily for language-based verification) at Runtime Verification include modeling of the Algorand protocol and verifying its safety, and modeling and verifying Ethereum’s finality mechanism in Casper. We have also developed the language-independent program verification framework in Coq that we use here for our working example described in this post, which is explained in more detail here.
The Working Example
Since our goal here is to highlight some of the main differences when using K versus Coq for program verification, we use a very simple, but meaningful example, which is the program SUM below, written in an imperative C-like language we call IMP:

Our working example program SUM
An important property we would want to verify about SUM is that, upon termination, the variable sum can only have the value (n + 1) n / 2 (which is the summation of integer values from 1 through n) for any non-negative integer n. We use this verification example to illustrate how K and Coq compare and contrast as language frameworks and give the reader a feel of the workflow involved in this process for each framework.
The complete specification of this example in both K and Coq and the verification scripts are all available here.
What We Need
Regardless of which framework we choose to use, the following three artifacts are generally needed for verifying programs correct:
- A formal model L of the syntax and semantics of the programming language whose programs you want to analyze. The model needs to be formal so that the syntax and semantics are well-defined and unambiguous, and so that it enables formal reasoning. Furthermore, it needs to be at a level of abstraction that makes it easy enough to argue about how faithful the model is to the intended semantics of the language. Essentially, L will be considered to be IMP from here on, and the only way to refer to the meaning of the IMP constructs is through L.
- A formal representation P in that model of the program to be analyzed. This is usually a model of the program structure as an Abstract Syntax Tree (AST) or an encoding of the program in some language. With the availability of supporting tools (namely, lexers and parsers that can generate the appropriate specification), it can also be the program text itself.
- A specification S of the property against which the program is to be verified. Depending on the model and the underlying formal logic for verification, this can be, for example, one or more temporal logic formulas, reachability logic assertions, preconditions and postconditions in Hoare triples, or formulas in first-order logic or other logical formalisms.
So what this means for SUM is that we will need to have:
- A formal model of the semantics of the language IMP, which defines precisely what the constructs of the language, such as
whileand assignment=, mean (irrespective of where they are used in programs). - A precise specification of the structure of the program SUM.
- A formalization of the property that the computed value is indeed the sum of integers from 1 through
n.
Language Frameworks vs. Conventional Program Verifiers
It is insightful to distinguish between a framework, like Coq and K, and a conventional program verifier. Conventional program verifiers are crafted for specific programming languages, such as VCC for C, Verisol for Solidity, etc., which means that the chosen language semantics L is hardwired in the tool itself. Moreover, conventional program verifiers usually also provide language-specific mechanisms to extract the program structure P from the program itself, as well as the specification S from user-friendly syntactic sugar annotations to the program. These make the program verifier easier to use and more user friendly, but come at the expense that the tool is essentially limited to the specific programming language (version) and property formalism for which it was created. Any changes to the programming language, for example migrating from one version to the next, or to the property formalism, for example adding a new logical or assertion construct, require the entire program verification tool itself to be updated by its developers or maintainters, if still available, and the users of the tool to wait until this is done and then switch to an essentially new tool.
Language frameworks are fundamentally different, in that the tools themselves are implemented independently from the languages to which they are applied. This separation of concerns allows the tools to be developed and advanced independently, at the same time isolating the language semantics as a standalone formal artifact valuable in itself (see, e.g., EVM Jellopaper, which currently acts as the canonical specification of the Ethereum Virtual Machine language). The price to pay is a potentially less friendly formal notation.
Therefore, the general program verification workflow in a language framework consists primarily of the following steps:
- Define formally the language structure (syntax) and use it to specify the structure of the program P.
- Define the formal semantics of the language, and use the developed language model L (syntax and semantics) to explore the program’s behavior.
- Specify the property S, and verify that the property S holds for P in L, or show that it does not hold.
This is the first part of a three-part post. In the rest of the first part, we will show how formal models of the syntax of IMP and the program SUM can be built in K and Coq (the first step in the workflow outlined above). Defining IMP’s semantics and testing execution of SUM (the second step) is explained in Part 2. The third step, which is specifying and verifying the correctness property, is described in Part 3.
Defining IMP’s Syntax
The first step in defining a formal model L of a language is defining its syntactic structures. Below, we define the syntax of the language IMP.
Syntax Definition in K
K has as its underlying logic Matching Logic, but it includes several features that are specifically engineered for defining languages. First, a programming language syntax can be given in the standard and widely accepted BNF format, along with structural and semantic annotations, such as associativity and evaluation order annotations. For example, arithmetic expressions of IMP are defined using the production rules below:

Syntax in K of IMP's arithmetic expressions
The rules specify a syntactic category for arithmetic expressions (introduced using the syntax keyword). A terminal is given as a double-quoted string, while a non-terminal is given by a name that begins with an uppercase letter. Int and Id are non-terminals for integers and identifiers, respectively.
Several annotations are used: > denotes precedence among operators, left for a left-associative binary operator, and strict for specifying the evaluation order. The annotation bracket means that parentheses ( ) are used only for grouping expressions and should not have dedicated nodes created for them in the parse tree (see the K tutorial for more details). Note that Coq does not need these kinds of annotations since Coq does not deal with parsing.
Boolean expressions BExp, like relational expressions, and program statements Stmt, like conditional and looping constructs, are defined using similar production rules.
Finally, Pgm is the syntactic category of programs in IMP, and every syntactically valid IMP program, like SUM above, has Pgm as its sort through this specification (Ids is a list of identifiers):

Syntax in K of IMP programs
Therefore, a program in IMP consists of a sequence of variable declarations followed by the program statement.
The complete K module that defines the syntax of the language IMP can be found here.
Syntax Definition in Coq
Coq has as its underlying logic the Calculus of Inductive Constructions. Therefore, to define IMP, the most natural approach is to specify IMP’s syntax using inductively defined data types and its semantics using inductively defined functions and relations.
For example, the syntax of arithmetic expressions in IMP can be defined in Coq using the following inductive type declaration introduced with the Inductive keyword (string and Z are the string and integer types in Coq):

Syntax in Coq of IMP's arithmetic expressions
Generally, each language construct with which an arithmetic expression in IMP can be built, e.g. variables, is captured by a constructor in the type AExp that specifies the types of its arguments. For example a variable is constructed by the constructor var applied to a string (the variable’s name), while a constant value is constructed by con applied to an integer. Using this definition, the expression x + 2, for instance, is represented by a term in Coq of type AExp having the form plus (var “x”) (con 2).
The syntax of Boolean expressions and statements in IMP is similarly defined, with inductive types BExp and Stmt, respectively. For example, the constructor for the while loop statement while : BExp -> Stmt -> Stmt takes two arguments: the condition as a Boolean expression and the body of the loop as a statement.
An IMP program of type Pgm is constructed by pgm, which takes as arguments a list of strings (the variables being declared) and the program statement:

Syntax in Coq of IMP programs
The complete Coq definition of the IMP (abstract) syntax can be found here.
Note that this encoding of IMP programs into terms in Coq corresponds to constructing parse trees of programs. This encoding process is necessarily manual, however, since Coq does not provide features specific to parsing programs into terms of inductive types (like associativity or operator precedence annotations in K). Furthermore, these Coq terms (parse trees) are purely syntactic. They have no semantic information associated with them at this stage. There is no K-style facilitation for specifying strictness of operators or other evaluation strategies in Coq, for instance.
Specification of SUM in K and Coq
The BNF style of K for specifying IMP’s syntax and the annotations used enable parsing of program text into an Abstract Syntax Tree (AST) that unambiguously defines the program structure. So the heavy lifting of specifying a program’s structure is taken care of automatically by the K parser for IMP generated from the BNF specification of the syntax. This means that the program text itself can be used directly for execution, verification, or by any other K tool. Below, we give a name sum_pgm parametric in n to the program text:
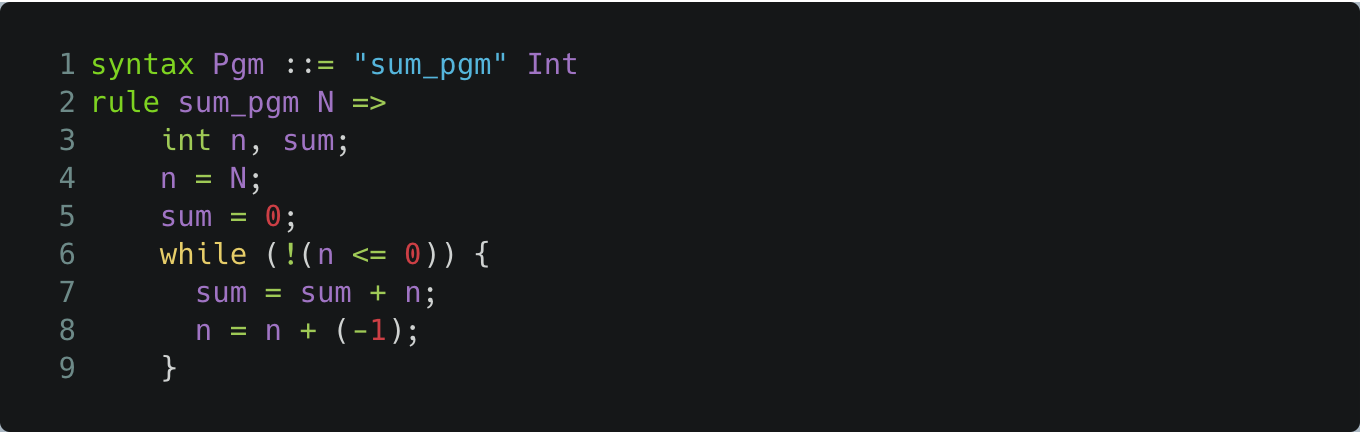
K Definition of SUM
Note that the K rule above, introduced with the rule keyword, defines the meaning of the term sum_pgm applied to an integer value. For example, sum_pgm 100 is the SUM program with the variable n initialized to 100.
However, in Coq, program texts, such as SUM above, cannot be directly used and need to be parsed into corresponding terms that are valid in the Coq model. For small languages and programs, like IMP and SUM, this parsing task is quite straightforward, but for more complex languages and larger programs, this process normally requires developing external parsers and Coq specification generators, which can be a non-trivial task.
In our Coq model, the program SUM has the following representation as a term of type Pgm, which we name sum_pgm as above:
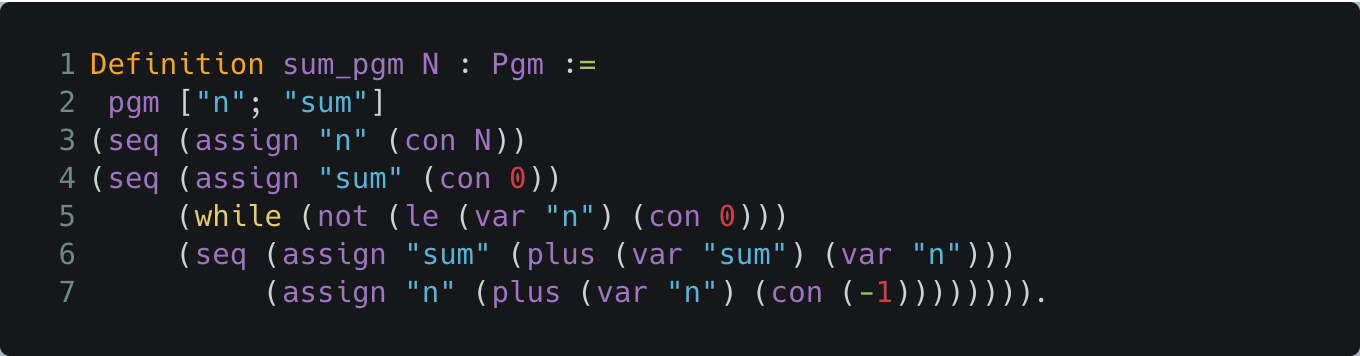
Coq Definition of SUM
The constructors seq and assign denote, respectively, sequencing and assignment statements in IMP (see the full definition here).
Next-up: the semantics ...
Now that we have a formal definition of the syntax of IMP and a formal representation of SUM, the next step is to define formally the semantics of IMP and test execution of SUM using the semantics. This is described next in Part 2 of this post.